UPDATE 20140227: I am leaving this post here for historical reference, but the version of SLOB I used while writing on it is now fully deprecated. Please go directly to the distribution page for SLOB2 and use the information there to retrieve the latest version of SLOB and learn how to use it, as the usage and functionality have changed. For additional tips, consider Yury’s “SLOB2 Kick start“. Please do not attempt to use the scripts, instructions or techniques I have described here unless you are still using the old version of SLOB. If you are still using the old version, you should not be.
Update 20130212: Please consider this a work in progress. I am re-running most of these tests now using the same LUN for every filesystem to exclude storage-side variance. I am also using some additional init parameters to disable Oracle optimizations to focus the read tests more on db file sequential reads and avoid db file parallel reads. My posts so far document the setup I’ve used and I’m already noting flaws in it. Use this and others’ SLOB posts as a guide to run tests on YOUR system with YOUR setup, for best results.
Update 20130228: I have re-run my tests using the same storage LUN for each test. I have updated the charts, text, and init parameters to reflect my latest results. I have also used a 4k BLOCKSIZE for all redo log testing. Further, instead of running each test three times and taking the average, I have run each test ten times, dropped the highest and lowest values, and averaged the remaining eight, in hopes of gaining a more accurate result. Where I have changed my setup compared to the original post, I have left the old text in, struck out like this.
In Part 1 and Part 1.5 I covered the setup and scripts I’ve used to benchmark performance of various filesystems (and raw devices) using SLOB for Oracle datafiles and redo logs. In this post I will provide more details, including the results and database init parameters in use for my tests. This is an SAP shop so I have several event and _fix_control parameters in place that may have performance impacts. SAP says “use them” so I wanted my tests to reflect the performance I could hope to see through the SAP applications,
I do not intend these tests to demonstrate the maximum theoretical I/O that our hardware can push using each filesystem. I intend them to demonstrate what performance I can expect if I were to change the databases to use each listed filesystem while making minimal (preferably zero) other changes to our environment. I know, for example, that adding more network paths or faster ethernet or splitting the bonded paths will improve Oracle direct NFS performance, but I am testing with what we have available at the moment, not what we COULD have.
Now that 11g is certified on Oracle Linux 6, we are building out an OL6.3 box and I will be running identical tests on that server in a couple weeks. I’m expecting to see some significant improvement in BTRFS performance there.
With that said, some information on the test environment:
- Server OS: SLES 11SP2 (kernel 3.0.51-0.7.9-default)
- Oracle version: 11.2.0.3.2 (CPUApr2012 + SAP Bundle Patch May2012)
- 2 CPU sockets, 8 cores per socket, with hyper-threading (Oracle sees CPU_COUNT = 32 but I have set CPU_COUNT to 2 to allow me to create a very small buffer cache)
- All filesystems and raw devices created within a single volume in a single NetApp storage aggregate
- I use only single instance databases so no effort was made to test cluster filesystems or RAC performance
Some notes about each test:
- All tests run in NOARCHIVELOG mode — obviously you should not do this in production
- Each filesystem was tested by creating SLOB users in a single tablespace containing a single
16GB4GB datafile on the indicated filesystem - All redo logs created with 4k blocksize
- All datafiles created with default parameters, I did not specify anything other than size and filename
- Read-only tests run with a
64M32M db_cache_size to force PIO - Redo generation tests run with a large log_buffer and two 32GB redo logs on the listed filesystem, with a 32G db_cache_size. I also set log_checkpoint_timeout to 999999999 to avert time-based checkpoints.
XFS redo testing performed with filesystemio_options=none, as otherwise I could not create redo logs on XFS without using an underscore parameter and specifying the sector size when creating the logs (see http://flashdba.com/4k-sector-size/ for more information on this issue). All other tests used filesystemio_options=setall; only XFS redo required none.All tests run with filesystemio_options=setall.- Read-write tests run with three 64MB redo logs stored on raw devices and 128M db_cache_size
- Every test was run
threeten times with 8 sessions,threeten times with 16 sessions, andthreeten times with 32 sessions, and an overall average was taken after dropping high and low values.Prior to each batch of tests the database was bounced.Per Kevin Closson’s recommendation, I executed a throwaway SLOB run after each bounce, discarding the results. “NFS” refers to Oracle direct NFSI dropped the NFS tests, as our ethernet setup is currently only 1Gb and does not perform as well as FC- Automated tasks like the gather stats job, segment and tuning advisors were disabled
- The BTRFS volume was mounted with nodatacow to avoid copy-on-write
Results
Oracle’s standard license prohibits publication of customer publication of benchmark results without express written consent. To avoid any confusion that these results represent a benchmark, I am NOT publishing any of the absolute numbers. Instead I have scaled all results such that the performance of a RAW device is equal to 1, and all other results are reported relative to RAW. I make no claims that these results represent the best possible performance available from my software/hardware configuration. What they should accurately reflect, though, is what someone with a similar setup could expect to see if they were to create redo logs or datafiles on the indicated filesystem without performing any tuning to optimize the database, OS or filesystem.
Comments
I am disappointed with the performance of BTRFS. Our OS vendor is deprecating ext4 in favor of BTRFS so if we’re going to abandon ext3 due to fsck issues BTRFS is the path of least resistance. Ext4 appears to provide performance similar to ext3 and should reduce fsck runtimes so if we stay on cooked devices that looks like the way to go. Raw performance won overall (though storage write caching appears to have made ext3 look better than raw) but it has management issues such as the 255-device limit and inability to extend a datafile on a raw device. ASM should provide the same overall performance as raw without the limitations, but adds additional management overhead with the need to install Grid Infrastructure and that just gives one more target to keep up to date on patches. XFS had poor performance for redo logs in my environment but good performance elsewhere, and it should entirely avoid fsck-on-boot problems.
Direct NFS seemed to deliver the most consistent performance from test to test, with a smaller standard deviation than any of the others. This might be relevant for anyone who requires consistent performance more than maximal performance.
Read Performance
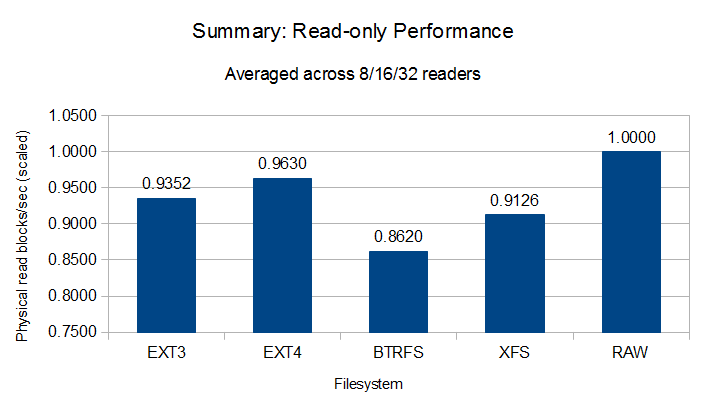
Scaled read performance
Redo Generation Performance

Scaled redo generation performance
Read/Write Performance

Scaled read/write performance
Init Parameters
Below are the init parameters used for each test. Note that filesystemio_options had to be set to none for the XFS redo generation testing, but other than that these parameters are accurate for all the tests.
Read Performance
SLOB.__db_cache_size=34359738368 SLOB.__oracle_base='/oracle/SLOB'#ORACLE_BASE set from environment SLOB.__shared_pool_size=704643072 *._db_block_prefetch_limit=0 *._db_block_prefetch_quota=0 *._db_file_noncontig_mblock_read_count=0 *._disk_sector_size_override=TRUE *._fix_control='5099019:ON','5705630:ON','6055658:OFF','6399597:ON','6430500:ON','6440977:ON','6626018:ON','6972291:ON','8937971:ON','9196440:ON','9495669:ON','13077335:ON'#SAP_112031_201202 RECOMMENDED SETTINGS *._mutex_wait_scheme=1#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._mutex_wait_time=10#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optim_peek_user_binds=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_adaptive_cursor_sharing=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_extended_cursor_sharing_rel='NONE'#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_use_feedback=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *.audit_file_dest='/oracle/SLOB/saptrace/audit' *.compatible='11.2.0.2' *.control_file_record_keep_time=30 *.control_files='/oracle/SLOB/cntrl/cntrlSLOB.dbf','/oracle/SLOB/cntrlm/cntrlSLOB.dbf' *.cpu_count=1 *.db_block_size=8192 *.db_cache_size=33554432 *.db_files=500 *.db_name='SLOB' *.db_recovery_file_dest_size=8589934592 *.db_recovery_file_dest='/oracle/SLOB/fra' *.db_writer_processes=2 *.diagnostic_dest='/oracle/SLOB/saptrace' *.event='10027','10028','10142','10183','10191','10995 level 2','38068 level 100','38085','38087','44951 level 1024'#SAP_112030_201112 RECOMMENDED SETTINGS *.filesystemio_options='SETALL' *.local_listener='LISTENER_SLOB' *.log_archive_dest_1='LOCATION=/oracle/SLOB/arch/SLOBarch' *.log_archive_format='%t_%s_%r.dbf' *.log_buffer=14221312 *.log_checkpoints_to_alert=TRUE *.max_dump_file_size='20000' *.open_cursors=1600 *.optimizer_dynamic_sampling=6 *.parallel_execution_message_size=16384 *.parallel_max_servers=0 *.parallel_threads_per_cpu=1 *.pga_aggregate_target=10737418240 *.processes=800 *.query_rewrite_enabled='FALSE' *.recyclebin='off' *.remote_login_passwordfile='EXCLUSIVE' *.remote_os_authent=TRUE#SAP note 1431798 *.replication_dependency_tracking=FALSE *.resource_manager_plan='' *.sessions=800 *.sga_max_size=10737418240 *.shared_pool_size=5242880000 *.star_transformation_enabled='TRUE' *.undo_retention=432000 *.undo_tablespace='PSAPUNDO'
Redo Generation Performance
SLOB.__db_cache_size=34359738368 SLOB.__oracle_base='/oracle/SLOB'#ORACLE_BASE set from environment SLOB.__shared_pool_size=704643072 *._db_block_prefetch_limit=0 *._db_block_prefetch_quota=0 *._db_file_noncontig_mblock_read_count=0 *._disk_sector_size_override=TRUE *._fix_control='5099019:ON','5705630:ON','6055658:OFF','6399597:ON','6430500:ON','6440977:ON','6626018:ON','6972291:ON','8937971:ON','9196440:ON','9495669:ON','13077335:ON'#SAP_112031_201202 RECOMMENDED SETTINGS *._mutex_wait_scheme=1#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._mutex_wait_time=10#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optim_peek_user_binds=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_adaptive_cursor_sharing=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_extended_cursor_sharing_rel='NONE'#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_use_feedback=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *.audit_file_dest='/oracle/SLOB/saptrace/audit' *.compatible='11.2.0.2' *.control_file_record_keep_time=30 *.control_files='/oracle/SLOB/cntrl/cntrlSLOB.dbf','/oracle/SLOB/cntrlm/cntrlSLOB.dbf' *.cpu_count=1 *.db_block_size=8192 *.db_cache_size=34359738368 *.db_files=500 *.db_name='SLOB' *.db_recovery_file_dest_size=8589934592 *.db_recovery_file_dest='/oracle/SLOB/fra' *.db_writer_processes=2 *.diagnostic_dest='/oracle/SLOB/saptrace' *.event='10027','10028','10142','10183','10191','10995 level 2','38068 level 100','38085','38087','44951 level 1024'#SAP_112030_201112 RECOMMENDED SETTINGS *.filesystemio_options='SETALL' *.local_listener='LISTENER_SLOB' *.log_archive_dest_1='LOCATION=/oracle/SLOB/arch/SLOBarch' *.log_archive_format='%t_%s_%r.dbf' *.log_buffer=268427264 *.log_checkpoint_timeout=99999999 *.log_checkpoints_to_alert=TRUE *.max_dump_file_size='20000' *.open_cursors=1600 *.optimizer_dynamic_sampling=6 *.parallel_execution_message_size=16384 *.parallel_max_servers=0 *.parallel_threads_per_cpu=1 *.pga_aggregate_target=10737418240 *.processes=800 *.query_rewrite_enabled='FALSE' *.recyclebin='off' *.remote_login_passwordfile='EXCLUSIVE' *.remote_os_authent=TRUE#SAP note 1431798 *.replication_dependency_tracking=FALSE *.resource_manager_plan='' *.sessions=800 *.sga_max_size=68719476736 *.shared_pool_size=5242880000 *.star_transformation_enabled='TRUE' *.undo_retention=432000 *.undo_tablespace='PSAPUNDO'
Read/Write Performance
SLOB.__db_cache_size=34359738368 SLOB.__oracle_base='/oracle/SLOB'#ORACLE_BASE set from environment SLOB.__shared_pool_size=704643072 *._db_block_prefetch_limit=0 *._db_block_prefetch_quota=0 *._db_file_noncontig_mblock_read_count=0 *._disk_sector_size_override=TRUE *._fix_control='5099019:ON','5705630:ON','6055658:OFF','6399597:ON','6430500:ON','6440977:ON','6626018:ON','6972291:ON','8937971:ON','9196440:ON','9495669:ON','13077335:ON'#SAP_112031_201202 RECOMMENDED SETTINGS *._mutex_wait_scheme=1#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._mutex_wait_time=10#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optim_peek_user_binds=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_adaptive_cursor_sharing=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_extended_cursor_sharing_rel='NONE'#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *._optimizer_use_feedback=FALSE#RECOMMENDED BY ORACLE/SAP FOR 11.2.0 - SAP note 1431798 *.audit_file_dest='/oracle/SLOB/saptrace/audit' *.compatible='11.2.0.2' *.control_file_record_keep_time=30 *.control_files='/oracle/SLOB/cntrl/cntrlSLOB.dbf','/oracle/SLOB/cntrlm/cntrlSLOB.dbf' *.cpu_count=1 *.db_block_size=8192 *.db_cache_size=134217728 *.db_files=500 *.db_name='SLOB' *.db_recovery_file_dest_size=8589934592 *.db_recovery_file_dest='/oracle/SLOB/fra' *.db_writer_processes=2 *.diagnostic_dest='/oracle/SLOB/saptrace' *.event='10027','10028','10142','10183','10191','10995 level 2','38068 level 100','38085','38087','44951 level 1024'#SAP_112030_201112 RECOMMENDED SETTINGS *.filesystemio_options='SETALL' *.local_listener='LISTENER_SLOB' *.log_archive_dest_1='LOCATION=/oracle/SLOB/arch/SLOBarch' *.log_archive_format='%t_%s_%r.dbf' *.log_buffer=268427264 *.log_checkpoint_timeout=99999999 *.log_checkpoints_to_alert=TRUE *.max_dump_file_size='20000' *.open_cursors=1600 *.optimizer_dynamic_sampling=6 *.parallel_execution_message_size=16384 *.parallel_max_servers=0 *.parallel_threads_per_cpu=1 *.pga_aggregate_target=10737418240 *.processes=800 *.query_rewrite_enabled='FALSE' *.recyclebin='off' *.remote_login_passwordfile='EXCLUSIVE' *.remote_os_authent=TRUE#SAP note 1431798 *.replication_dependency_tracking=FALSE *.resource_manager_plan='' *.sessions=800 *.sga_max_size=34359738368 *.shared_pool_size=5242880000 *.star_transformation_enabled='TRUE' *.undo_retention=432000 *.undo_tablespace='PSAPUNDO'
Supplementary Data
I have removed the content of this section on 20130228 as it related to my previous results and not the updated results now contained in this posting.

Great research. Some questions if you’ll allow:
1. I think we sent you the necessary 11.2.0.3 hidden param to allow a 4K blocksize redo log. Did you get a chance to try that with XFS?
2. Did you collect any xfs_bmap -v output from the XFS files? Please forgive if you did and even sent them to me because things are a bit hectic at the moment for me
3. If you still have the XFS mount could you run xfs_info on the mount to see the number of AGs?
4. Any chance you could use awr_info.sh and post up latency numbers?
Should be able to get most or all of that — off at the mountain today though 🙂
There is (yet) another XFS experiment I would try. Look at that fallocate kit I sent you. Pull out it’s use of my little allocate_file program and use that to create fresh online redo logs then add those to the database with REUSE. I don’t think any of this leads to solution space, it’s just to study varying remedies to what little file system fragmentation you might be suffering. I say “might” because we won’t know until we see xfs_bmap -v output.
Good stuff.
Hi Kevin,
All of the volumes are still there so I can gather more info. We’re planning to swing these volumes over to the upcoming OL6.3 box for some more testing. I’m thinking it, or at least the UEK kernel will have a newer/better/more performant BTRFS driver.
1. The hidden param allowed me to create redo logs on XFS without filesystemio_options set to none. I didn’t SLOB that setup, though. It’s worth doing.
2. I did mail you xfs_bmap output, but I’m editing this post to add a supplementary data section and including it there.
3, 4: See edits.
Frustrating to see redo logs spanning 8 and 6 allocation groups. I would be curious to see if a defragged redo would improve your LGPW latencies. The following are 135ms->941ms !
Can you shut the database down and reun that defrag kit I sent you. You could easily edit that defrag.sh and change the find command to only produce the path to the redo logs. That works just fine…
REDO/SLOB-AWR-XFS-1.16.0| 0| 0|241679
REDO/SLOB-AWR-XFS-1.32.0| 0| 0|142322
REDO/SLOB-AWR-XFS-1.8.0| 6711| 0|927536
REDO/SLOB-AWR-XFS-2.16.0| 0| 0|384810
REDO/SLOB-AWR-XFS-2.32.0| 0| 0|201588
REDO/SLOB-AWR-XFS-2.8.0| 7092| 0|955224
REDO/SLOB-AWR-XFS-3.16.0| 0| 0|148504
REDO/SLOB-AWR-XFS-3.32.0| 0| 0|135996
REDO/SLOB-AWR-XFS-3.8.0| 0| 0|941176
I can give that a shot and rerun the tests but they’ll take a while.
Any value in defragging the datafile too?
Also, I think the version of awr_info.sh is not the latest. The latest is in the SLOB tarball at the OakTable site. It breaks out num-writers and num-readers into pipe-delimited columns so as to make an even better tuple to paste into excel.
That was from the Feb drop on OakTable, I pulled out filename and latency with cut to limit the output columns — sed ‘s/\./|/g’ or similar should reproduce readers/writers from the filename format. I can also re pastebin it with those cols in too.
yeah, I prefer the output this version produces. I need to fold this into the SLOB tarball. I like the READER WRITER columns…I can, of course, make all that from your pastebin stuff though.
http://oaktable.net/contribute/slob-awrinfosh-script
Hi Brian,
So I see defrag.sh make differently-fragmented redo. Hmmm. How many total files are there in that mount? (find -type f -print | wc -l).
Also, could you please create a file in the same directory as redo[12].dbf as follows:
$ ./allocfile foo 34359738880
then :
$ sudo xfs_bmap -v foo
thanks.
Similar looking xfs_bmap on the newly created allocfile. Only two other files were in the directory besides the redo logs, just allocfile and the defrag shell script.
I think tomorrow I may just try recreating the filesystem.
Hi,
Great article.
One of my customers experienced a severe performance regression after applying SLES 11 SP2 and hence moving from kernel 2.6.32 to 3.0.51. We used SLOB to reproduce the workload and there is no way the system could sustain the workload on SP2.
Greetings,
Alexis
Thanks for the response.
I’m curious, if you can share that information, which filesystems your client was using that experienced this regression. We have been on 3.0.42 and 3.0.58 on our SLES 11SP2 boxes, and haven’t noticed issues other than unexpected fsck runs after clean shutdowns. But I suspect your customer’s systems are more heavily loaded than ours.
Hi Brian,
Actually, we’re using ext3. We have 3 filesystems accessed concurrently by spreading datafiles over them (SLOB database).
As an example of a workload, this is what we see with a runit 8 8 session (setup with 256 users):
14:30:01 CPU %user %nice %system %iowait %steal %idle
14:30:01 all 0.02 0.00 0.05 0.00 0.00 99.92
14:40:01 all 0.37 0.00 0.31 9.87 0.00 89.45
14:50:01 all 0.44 0.00 0.41 14.81 0.00 84.34
15:00:01 all 0.24 0.00 0.14 6.34 0.00 93.27
14:30:01 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
14:40:01 dev4-0 2128.45 15881.83 20201.07 16.95 9.32 4.38 0.31 66.92
14:40:01 dev250-0 738.78 5334.66 5928.78 15.25 3.66 4.96 0.90 66.75
14:40:01 dev250-1 705.29 5117.08 5527.66 15.09 3.55 5.03 0.95 66.70
14:40:01 dev250-2 764.15 5430.44 8739.08 18.54 2.17 2.85 0.83 63.47
14:50:01 dev4-0 3106.86 22754.22 29781.48 16.91 13.95 4.49 0.32 100.02
14:50:01 dev250-0 1071.13 7669.20 8173.44 14.79 5.47 5.11 0.93 99.78
14:50:01 dev250-1 1034.82 7341.82 8279.58 15.10 5.28 5.10 0.96 99.75
14:50:01 dev250-2 1117.03 7743.19 13322.89 18.86 3.29 2.94 0.84 94.14
Dev4 contains the swap partition.
At a mixed runit 32 32 load, iowait jumps over 35% and the server freezes.